Table of Contents
- Introduction
- History and Characteristic of WIDE 6bone
- Technical Topics of IPv6
- Translator
- Future Plans
- Conclusion
- Acknowledgements
- References
1. Introduction
Since the IPv4 address space is being exhausted due to the rapid growth of the Internet, it is of recent interest to develop IPv6 and to migrate to IPv6 environments without great confusion. To deal with this problem, WIDE Project has formed IPv6 working group in the summer of 1995.WIDE Project is a research consortium in Japan focused on the Internet and related technologies. A few hundred researchers in universities and companies are involved. WIDE Project operates test-bed networks called WIDE Internet since 1988 including nation-wide backbone as well as international connectivities.
In the late of 1995, the working group had four independent IPv6 implementations and interoperability had been tested on local networks. To test the implementations against live traffic and to activate IPv6 developments, it was highly desired to deploy IPv6 test-bed networks to interconnect the sites involved in the IPv6 development by IPv6 over IPv4 tunnels and native data-links on top of the WIDE infrastructure.
We started deploying our IPv6 network, called WIDE 6bone in June, 1996. Currently, WIDE 6bone is one of the largest IPv6 test-beds and is playing a role of core site in world-wide 6bone. Various data-links including serial links and ATM PVCs are used while other 6bone sites typically use tunnels only.
Through the operation of WIDE 6bone, we found some unique topics to IPv6, including a source address selection algorithm, a renumbering procedure, and application dilemmas on dual stack environments. We also developed three translators for smooth migration from IPv4 to IPv6.
This paper is an activity report of IPv6 working group of WIDE Project with the hope that our experiences provide useful information to those who will take similar approaches. It is organized as follows: Section 2 describes the history and characteristic of WIDE 6bone Experienced topics and translators are explained in Section 3 and Section 4, respectively. We mention our future plans in Section 5 and show conclusion in Section 6.
2. History and Characteristic of WIDE 6bone
During the 35th IETF at Los Angeles in March, 1996, Jon Postel, Bob Fink, Jun Murai, etc had a private meeting. They agreed to deploy world-wide 6bone connecting America, Europa, and Asia-Pacific rim. WIDE Project decided to deploy WIDE 6bone by the next IETF meeting.At 15:22 on June 9 (JST), the first IPv6 packet made a round trip between Nara Institute of Science and Technology (NAIST) and WIDE Tokyo NOC. This moment is the birth of WIDE 6bone. The connectivity between them was not an IPv6 in IPv4 tunnel but a serial link.
We split a T1 circuit into two data-links: 1472 Kbps and 64 Kbps. The 1472 Kbps link was used to connect the regular IPv4 network while the 64 Kbps link was assigned to IPv6 network. This method eliminated payment of an additional leased line. This also prevented that the IPv6 network would affect the IPv4 network operation.
The University of Tokyo was also connected to Tokyo NOC and packets from NAIST to the university was routed on the same day. Osaka University joined to WIDE 6bone after a week. At this time, IPv4 compatible IPv6 addresses[4] were used just for convenience and routing was managed manually due to the lack of routing daemons.
At 6bone BOF on the 36th IETF at Montreal in June, 1996, several activities including WIDE Project were introduced. Consensus was achieved to establish world-wide 6bone on July 15. WIDE Project raised its hand for participation. Toward the promised day, WIDE Project renumbered IPv4 compatible IPv6 addresses to the old IPv6 test addresses[6]. Cisco systems became the first peer of WIDE Project on July 16. An IPv6 in IPv4 tunnel was also deployed with G6 on July 18. Since then, WIDE 6bone provided packet transit service for the world-wide 6bone as one of the core members.
Since number of participants gradually increased, static routing was becoming unmanageable. So, we developed a RIPng[8] daemon then installed it onto the routers in WIDE 6bone in February, 1997. A half of year later, hops within WIDE 6bone exceeded 10 and the number of full routes in world-wide 6bone reached 300.
To resolve RIPng mess and to test the new address architecture[5], ngtrans working group of IETF, where 6bone BOF activities absorbed, decided the followings on the 39th IETF at Munich in August:
- Renumber old provider based addresses into new aggregatable addresses.
- Migrate to BGP4+[1] by November 1.
WIDE Project was chosen as a pseudo top level aggregator (pTLA) site and 3ffe:500::/24 has been assigned. So, it carried out the second renumbering in October. Our experience of renumbering will be discussed later in Section 3.2. Since the development of BGP4+ daemon was delayed, migration to BGP4+ was accomplished in January, 1998.
Since some parts of our IPv4 backbone switched to ATM PVCs, we needed to find an alternative of the multiplexor technology. ATM can be considered a logical multiplexor but there was no specification to carry IPv6 packets over ATM PVC links. So, we wrote up an Internet-Draft[12] on this topic then migrated to this substitution.
As of this writing, about 10 independent implementations of IPv6 stack are being developed and are operated in WIDE 6bone and about 20 organizations are interconnected by serial links, ATM PVCs, and IPv6 over IPv4 tunnels. Figure 1 illustrates the current topology of WIDE 6bone. Comparing with other IPv6 networks, WIDE 6bone is characterized by the fact that many vendors are involved and heterogeneous data-link technologies are in use.
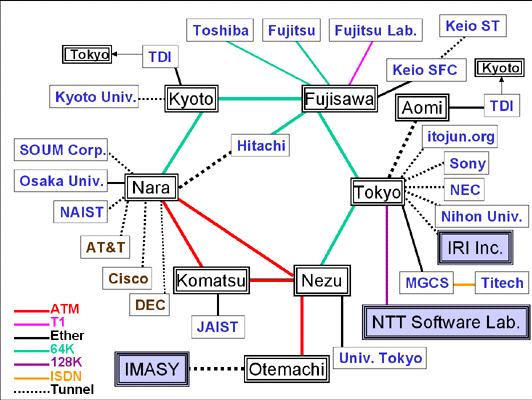
Figure 1. The current topology of WIDE 6bone. (15/04/98)
3. Technical Topics of IPv6
This section explains some topics that we learned through our operation of WIDE 6bone. Section 3.1 shows the source address selection algorithm. The smooth renumbering procedure and the application dilemmas are discussed in Section 3.2 and Section 3.3, respectively.3.1 Source Address Selection
Through the operation of WIDE 6bone, we realized that one of the key mechanisms for IPv6 is to select an IPv6 source address when initiating a communication. We simply call this "source selection". Following subsections discuss issues on scope rule, renumbering measures, preliminary policy routing, and interoperability then shows our proposed algorithm.3.1.1 Scope Rule
We first insist that source selection must be scope-oriented. As of this writing, we categorize IPv6 addresses to four scope-classes: node-local, link-local, site-local, and global. Node-local class consists of loopback address and node-local scope multicast addresses. Link-local class consists of unspecified address, link-local unicast addresses, and link-local scope multicast addresses. Site-local class consists of site-local unicast addresses and site-local scope multicast addresses. Global class consists of global unicast addresses and other scope multicast addresses.For convenience, we describe a scope class corresponding to an IPv6 address as SC(addr) and define the following total ordering:
node-local < link-local < site-local < global
To ensure communication, we conclude a basic principle for a given IPv6 packet as follows:
SC(src) = SC(r1) = SC(r2) = ... = SC(rn) = SC(dst)
where "src" is the source address, "dst" is the destination address, and r1, r2, ..., rn are addresses of intermediate nodes specified in the routing header if exist.
The background to introduce this principle is as follows:
- To ensure communication between two nodes, SC(src) must be
greater than or equal to SC(dst). That is,
SC(src) >= SC(dst)
must be satisfied. - If we choose a source address such that SC(src) < SC(dst), the packet would be delivered to the destination. However, it is likely that the reply packets from the destination are not delivered to the originating node.
- If two nodes are not on the same link, the following condition
must be satisfied according to 1):
SC(src) >= SC(r1) >= SC(r2) >= ... >= SC(rn) >= SC(dst)
Considering a reply packet, the following condition must be satisfied:SC(src) <= SC(r1) <= SC(r2) <= ... <= SC(rn) <= SC(dst)
Therefore, the following condition must be satisfied to ensure communication for two nodes which are not on the same link.SC(src) = SC(r1) = SC(r2) = ... = SC(rn) = SC(dst)
- If two nodes are on the same link, SC(dst) may be greater than SC(src) in normal environments. However, if an global address which is assigned to a different interface is selected, packets may traverse extra hops. Moreover, if the link is isolated, communication becomes impossible while direct communication is possible. So, to ensure communication within the link, SC(src) should be equal to SC(dst).
- Communication within one node can be accomplished with any addresses. It is a good idea, however, to apply the basic principle to node-local communication in order to make rules as simple as possible and to prevent accidents.
3.1.2 Renumbering Measures
Source selection must be robust enough against renumbering which has two big problems. One is communication within the site during renumbering and the other is aging of old addresses.Since a site-local address is chosen as source for a given destination whose scope-class is site-local according to our scope rule, communication within a site is ensured during renumbering. (Even if site-local addresses are not used, new global addresses are selected thanks to the longet match mechanism described later.)
A mechanism to expire addresses is defined [11]. When preferred lifetime is expired, an address becomes deprecated until valid lifetime expired. Deprecated addresses must not be candidate for source selection.
3.1.3 Preliminary Policy Routing
Source selection should provide policy routing mechanism if possible. One candidate to accomplish preliminary policy routing is longest match(this idea was originally proposed by Quaizar Vohra on the IPng mailing-list). Consider the following multi-homed example in Figure 2.
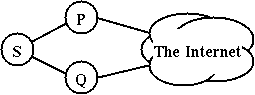
Figure 2. An example of multi-homed site.
Site "S" has two connections: one is to provider "P", the other is to provider "Q". Site "S" also has two global address block: "p:s" and "q:s" which is assigned by provider P and Q, respectively.
A typical requirement of site S is effective routing. Effective routing means that incoming packets should come back through the link where the outgoing packet was carried. If we use longest match against destination for source selection, this requirement is achieved in some cases.
When a host in site S intiates a communication in a host in provider P, the outbound packets are routed to the link P-S if the routing is well-managed at the border of site S. The reply pakcets are routed to the link P-S again if the initiating host choosed the source address of "p:s" rather than "q:s".
3.1.4 Interoperability
Lastly, source selection must provide high interoperability. The discussions above are on cases where a source address is not bound. But there are cases where it is already bound, typically found in TCP connection established by a remote host. It is very likely that the remote host violates our scope rule. Experience tells us that the best strategy for interoperability is to be liberal in what you receive and be conservative in what you send. So, use a bound source in reply packets rather than consider it an error.3.1.5 A Proposed Algorithm
Here is a source selection algorithm integrated the functions above, which is already implemented and well-tested in our IPv6 stack.- If a source address is already bound, use it.
- Select an interface to be used to output the packet by routing table lookup with the destination address. Then consider the addresses assigned to the interface to be the candidates.
- Remove anycast and multicast from candidates.
- Remove deprecated addresses from candidates.
- Remove addresses whose scopes are different with the scope of the destination address.
- If there is at least one address associated with the output interface, use the address(es) as candidate. In a case of global scope address, the address which has longest match with the destination address may be useful.
- If no appropriate address is found and scope-class is greater than or equal to site-local, then consider the set of addresses assigned to the host (regardless of the output interface). Then repeat 3) - 6).
- Return an error to the application if possible.
3.2 Renumbering
Twice renumbering events let us discuss this topic in detail. Renumbering on IPv6 environment is much more smooth than that on IPv4 thanks to router advertisement and stateless address configuration. Here is a procedure to carry out gentle renumbering.- Add new addresses to routers. Let the old addresses be deprecated.
- Announce new prefix information in router advertisement messages. Announce the old prefix information with short lifetime or stop announcing the old prefix information.
- Announce new routing information to others. Also continue to announce the old routing information.
- Update DNS information. For name-to-address lookup, configure DNS entries only with the new addresses. For reverse lookup, configure both the old and new addresses. At this time, new addresses are used in most communications.
- Wait for the expiration of the DNS resource records corresponding to the old addresses.
- Stop announcing the old routing information.
- Remove the old addresses on routers.
- Delete the old addresses for reverse lookup.
More research on this topic is still necessary to automate this procedure as much as possible. The key is probably automatic router renumbering which is being discusses in IPng working group, IETF.
3.3 DNS and dual stack
On dual stack environments, it is desired that differences of network layer are invisible to applications or users. Thanks to the protocol independent name-to-address function(i.e. getaddrinfo()) [3], it is straightforward to make clients protocol independent. For example, a user specifies a host name to telnet without a concern about whether it is an IPv6 host or an IPv4 host. The getaddrinfo() function resolves A and/or AAAA records making use of AF_UNSPEC magic and gives the results to telnet in the socket address structure which is protocol independent in the application point of view.
If servers are executed by Internet super daemon(i.e. inetd), they can also be protocol independent. But if they are implemented as stand-alone daemon, it is necessary to tell them which socket should be opened, AF_INET or AF_INET6 or both maybe by command line arguments.
Through our experience, we found two ambiguities in the dual stack environment. One is a common problem to all applications while the other is related with MX.
The getaddrinfo() function has the former ambiguity if AF_UNSPEC is specified. Consider this simple scenario. "host.foo" and "host.bar" are different host and has an IPv6 address, say A6, and an IPv4 address, say A4, respectively. Suppose that a search list to complete domain name is configured as "foo bar".
Let a user try to login executing "telnet host". If an implementation of the getaddrinfo() function tries to resolve with AF_INET first then AF_INET6 next, telnet connects to A4 (i.e. host.bar). If another implementation of the getaddrinfo() function tries in the reverse order, telnet connects to A6 (i.e. host.foo).
This problem is because there is no consensus on preference between address family and the search list. We believe that the search list is preferred to address family. In this case, results must be a list of A6 and A4 (i.e. host.foo then host.bar according to the search list) independent on how the getaddrinfo() function is implemented. We should make consensus on this.
E-mail delivery highly depends on MX record of DNS. In a dual stack environment, a MX record is associated with a list of FQDN, each of them is then associated with a set of IPv4 or IPv6 addresses. Given a MX record, a dual stack host can deliver messages to the most preferred MX host regardless of capability of the MX host. An IPv4 host, however, is able to send messages only to another IPv4 MX host. So is IPv6 host.
What happens within the same MX domain? If there is no reachability to the most preferred MX host in the domain, messages cannot reach to the final destination. So, in the dual stack environment, operators must be careful in reachability within their MX domain. One possible solution is to make the most preferred MX host dual stack.
NS record also has the same problem. Unfortunately, the solution above is not available for NS record since there is no preference for it.
4. Translator
In the early stage of the migration from IPv4 to IPv6, it is expected that IPv6 islands will be connected to the IPv4 ocean. On the other hand, in the late stage of the migration, IPv4 islands will be connected to the IPv6 ocean. IPv4 hosts will remain for a long run after the exhaustion of IPv4 address space. So, it is necessary to develop translators to enable direct communication between IPv4 hosts and IPv6 hosts. For convenience, let us categorize IPv4/IPv6 translator into four types(See Figure 3).
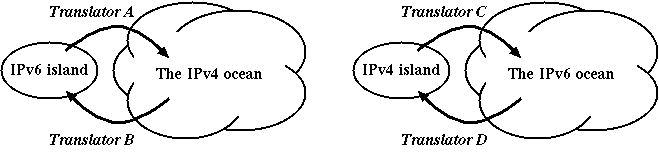
Figure 3. Translator categories.
- Translator A
- It is used in the early stage of transition to make it possible to establish a connection from an IPv6 host in an IPv6 island to an IPv4 host in the IPv4 ocean.
- Translator B
- It is used in the early stage of transition to make it possible to establish a connection from an IPv4 host in the IPv4 ocean to an IPv6 host in an IPv6 island.
- Translator C
- It is used in the late stage of transition to make it possible to establish a connection from an IPv4 host in an IPv4 island to an IPv6 host in the IPv6 ocean.
- Translator D
- It is used in the late stage of transition to make it possible to establish a connection from an IPv6 host in the IPv6 ocean to an IPv4 host in an IPv4 island.
- We cannot modify IPv4 hosts but can implement IPv6 hosts as we like.
- A small space of IPv4 address is also assigned to an IPv6 island according to the current severe address assignment policy.
- An IPv4 island can also obtain a large space of IPv6 address.
Typical translator consists of two components. One is interpretation between IPv4 packets and IPv6 packets discussed in Section 4.1. The other is address mapping between IPv4 and IPv6 explained in Section 4.2. Section 4.3 describes implementation status.
4.1 Interpretation of IPv4 and IPv6
For interpretation of IPv4 and IPv6, we can use two technologies. One is a traditional header conversion router like NAT[2]. The other is upper layer gateways to bridge an IPv4 connection and an IPv6 connection like SOCKS[7].Header conversion[9] is fast enough but has dilemmas in common with NAT. A good example is difficulty in translation of network level addresses embedded in application layer protocols, which are typically found in FTP and FOOBAR[10]. Header conversion is also suffered from problems which are not found in NAT: A large IPv4 packet is fragmented to IPv6 packets because header length of IPv6 is typically 20 bytes larger than that of IPv4. Semantics of ICMPv4 and that of ICMPv6 are not inter-changeable.
The upper layer approach is free from the dilemmas above since every connection is closed in each network protocol. We have implemented two translators of this kind based on SOCKS scheme and TCP relay.
SOCKS is a framework of remote procedure calls for socket operations. Since SOCKS maps port numbers on multiple hosts onto port numbers on a single node, only outgoing connections can be established. Thus, SOCKS scheme can be used for Translator A and C.
TCP relay server acts like man-in-the-middle. When a TCP packet reaches a relay server, the network layer tosses it up to the TCP layer even if the destination is not server's address. The server accepts this TCP packet and establishes a TCP connection to the source host. One more TCP connection is also made from the server to the real destination. Then the server reads data from one of two connections and writes the data to the other.
4.2 Address Mapping
Address mapping should be invisible both to IPv6 applications and to IPv4 applications. Typical approaches are library extensions on local hosts and DNS extensions.SOCKS is an example of library extensions. To install remote procedure call functions for socket operation, SOCKS clients are linked to SOCKS libraries. SOCKS protocol version 5 can make use of FQDN to tell a target host to a SOCKS server. Since FQDN is protocol independent, address mapping, more strictly connection mapping, is closed in the SOCKS server host.
Let's consider Translator C, for example. A SOCKS clients can make a TCP connection over IPv4 to a SOCKS server. Then an IPv6 target host is specified in FQDN by the client to the server. The server can resolve an IPv6 address concerned with the FQDN string, then connects to the IPv6 host. Of course, this mechanism can apply to Translator A.
Another approach is to extend DNS. For Translator A, for instance, an extended DNS server returns a temporary IPv6 address against a host name associated with IPv4 only. On this approach, we must ensure reachability of assigned addresses in each protocol and resolve a DNS cache problem. If we use TCP relay for interpretation, address mapping is necessary only for destination addresses since source address mapping is closed in the relay server. Discussions later assume TCP relay, so we focus on destination address mapping.
For Translator A, DNS extensions are straightforward since the address space of IPv6 is much larger than that of IPv4. A extended DNS receives a query to resolve AAAA records against an IPv4 host. The server can assign a temporary IPv6 address to embed the IPv4 address. This mapping can also be implemented by extensions of name-to-address libraries as described later in Section 4.3 because the mapping rule is static.
For Translator B, this approach is hard to implement. We have to map all IPv6 hosts inside to very small set of IPv4 addresses assigned to the site. IPv4 address assignment must be dynamic. Worse, we must take care of time to live of such dynamically assigned entries.
The DNS cache problem is closed in the site for Translator C. Moreover, we can use of fairly large space of IPv4 private address. It is dynamic to map an IPv6 address to an IPv4 private address but we can set long time to live.
Translator D is straightforward. We can assign an IPv6 address out of the assigned IPv6 space to each IPv4 host inside statically in advance. Since this is static assignments, no cache problem occurs.
4.3 Implementation Status
We have one implementation of header conversion router. It is designed to cover all types of translators with extended DNS server. But the DNS cache problem on Translator B has not resolved yet. Currently, we are testing it setting time to live of DNS entries to zero.Translator C based on SOCKS has been developed using the NEC's SOCKS package. This approach is very useful for SOCKS-ready environments. When SOCKS clients are IPv6-ready, this translator can act as Translator A thanks to the protocol independence feature of SOCKS protocol version 5.
We have implemented a TCP relay server of Translator A as a user level daemon, called faithd. We also modified our IPv6 stack implemented on FreeBSD so that it tosses up TCP segments destined to another host if a manager sets it to do so. For address mapping, we extended the getaddrinfo() function to map an IPv4 address to a specific IPv6 address block specified by an environment variable.
We linked many clients including telnet, rlogin, rsh, ftp, ssh to this function so that they become faithd-ready. Since we implemented our original name server which can handle UDP/IPv6 queries as well as UDP/IPv4 queries, the clients are completely IPv4 free. faithd can not only relay both normal and out-of-band TCP data but also can emulate TCP half close. It is also able to translate network level addresses in both the PORT and PASV FTP command. faithd is installed in WIDE 6bone to test its stability.
5. Future Plans
We are planning several advanced experiments using WIDE 6bone.We started assigning the fourth octet, pseudo NLA1, to non-WIDE member sites in Japan on request bases. This will provide us with environments where various experiments, including NLA1 assignment policy, multi-homing beyond TLA, are possible. In Figure 1, three boxes filled in gray are the NLA1 applicants.
Our original registry is now operational. This registry collects information of not only organizations under the pseudo NLA1 of WIDE Project but also under other NLA1s in Japan. These information is automatically registered and updated to the 6bone registry. We need more research on this topic if security and other aspects are in consideration.
It is necessary to implement Translator B immediately since some organizations will start using IPv6 equipment for their business presumably in this year. As mentioned above, Though DNS extensions for this kind of translator have the dilemmas above, we have some ideas to resolve them in our mind.
6. Conclusion
We don't know several things until we implement and run it.Through the operation experience of WIDE 6bone which is one of the biggest test-beds of IPv6, we learned importance of source address selection and renumbering, and noticed ambiguities of dual stack environments.
Our proposed algorithm of source selection is scope-oriented and robust enough against renumbering, and we found that it carries out preliminary policy routing for multi-homed networks. We explained the gentle renumbering procedure making use of stateless address configuration. On dual stack environments, it is necessary to achieve consensus on preference between protocol families and a domain search list. Also, operators working on e-mail delivery system must ensure reachability in the same MX domain.
To achieve smooth migration from IPv6 to IPv4, translator in the early stage needs to be implemented quickly. Outgoing connections from a site can be established with our programmed translator which is already running on WIDE 6bone. More research is necessary for incoming connections.
Acknowledgements
Our deep gratitude goes to other members of IPv6 working group, WIDE Project, for their support over the past years. We thank operators of world-wide 6bone for their cooperation.References
- T. Bates, R. Chandra, D. Katz, and Y Rekhter, Multiprotocol Extensions for BGP-4, RFC 2283, 1998.
- K. Egevang and P. Francis, The IP Network Address Translator (NAT), RFC 1631, 1994.
- R. Gilligan, S. Thomson, J. Bound, and W. Stevens, Basic Socket Interface Extensions for IPv6, RFC 2133, 1997.
- R. Hinden and S. Deering, IP Version 6 Addressing Architecture, RFC 1884, 1995.
- R. Hinden and S. Deering, IP Version 6 Addressing Architecture, Internet-Drafft, <draft-ietf-ipngwg-addr-arch-v2-06.txt>, 1998.
- R. Hinden and J. Postel, IPv6 Testing Address Allocation, RFC 1897, 1996.
- M. Leech, M. Ganis, Y. Lee, R. Kuris, D. Koblas and L. Jones, SOCKS Protocol Version 5, RFC 1928, 1996.
- G. Malkin and R. Minnear, RIPng for IPv6, RFC 2080, 1997.
- E. Nordmark, Stateless IP/ICMP Translator (SIIT), Internet-Draft, <draft-ietf-ngtrans-header-trans-01.txt>, 1997.
- D. Piscitello, FTP Operation Over Big Address Records (FOOBAR), RFC 1639, 1994.
- S. Thomson and T. Narten, IPv6 Stateless Address Autoconfiguration, RFC 1971, 1996.
- K. Yamamoto, K. Cho, Y. Inoue, H. Esaki, Y. Atarashi, and A. Hagiwara, IPv6 over Point-to-Point ATM Link, Internet-Draft, <draft-yamamoto-ipv6-over-p2p-atm-01.txt>, 1998.